How LLMs Figures Out What You Mean - No Math Degree Required
When you type a sentence into an AI, how does it figure out what you mean? In "Do lions roar?", how does it know that "roar" goes with "lions" and not with "Do"?
This post walks that whole path with no heavy math. We'll follow "Do lions roar?" from raw text all the way to the model deciding how each word relates to every other word in that three-letter sentence. Along the way we'll turn words into numbers, picture those numbers as arrows, measure how "close" two arrows are, and finally use that closeness to figure out how words relate to each other. By the end you'll have a clear mental picture of how an LLM reads a sentence and works out how the words relate.
Part 1: Words become numbers
A model can't do anything with letters as underneath the hood, it's all math, so before it can reason about a sentence, every word has to become a number, and then something richer than a number. This happens in two steps.
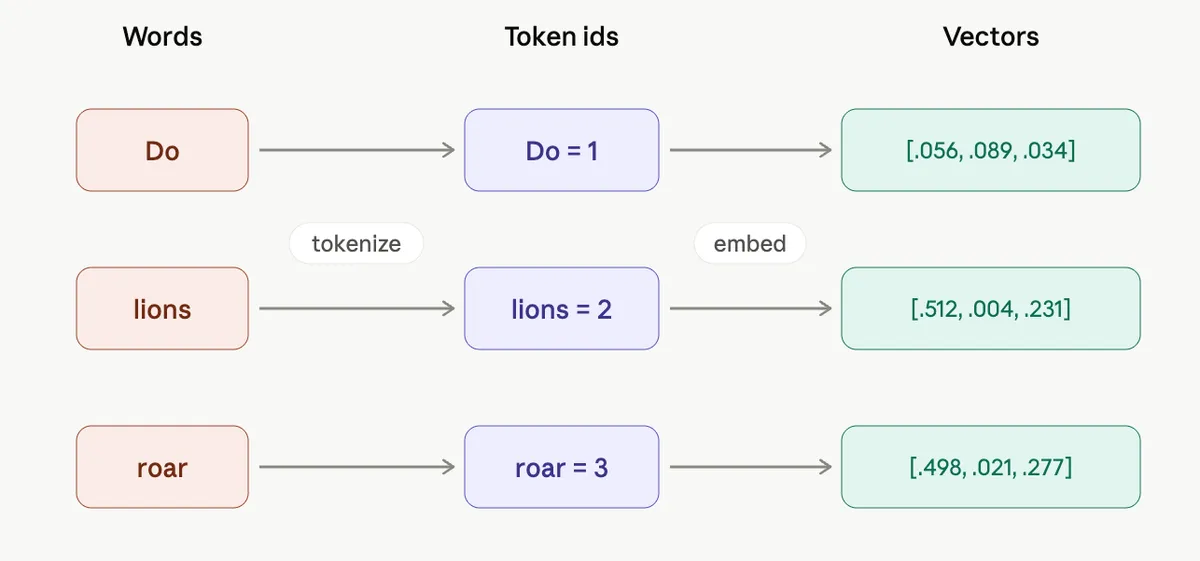
- Take a sentence: "Do lions roar?". Each word is a token (we are ignoring the question mark in this post, and more on that later).
- The model swaps each word for a plain number, its token id: Do → 1, lions → 2, roar → 3.
- Each token id then becomes a vector, which is just a list of numbers: 1 → [.056, .089, .034], and so on for the rest.
Why bother with a vector and not just leave the words as 1, 2, 3? Because a single number carries no meaning. Nothing about the number 2 ("lions") says it's any closer to 3 ("roar") than to 99. A vector fixes this by giving each word a whole list of numbers instead of one, and each slot in that list can later capture a little meaning. Words that mean similar things end up with similar lists, and that is what finally lets us compare them.
How long is that list? It can have as many slots (dimensions) as you like. More slots means more room to store meaning, which makes the model more precise. We're using three here to keep things readable (e.g., [.056, .089, .034]), but real models use hundreds or thousands.
Part 2: The goal is to model relationships
Numbers on their own don't tell us much. The interesting question isn't "what number is 'lions'?" but "how does 'lions' relate to the words around it?"
- What we actually want is how the words connect: "Do" vs "lions", "Do" vs "roar", "lions" vs "roar".
- So the real question becomes: how "close" is one word's vector to another's?
To answer that, we lean on one idea from linear algebra: the vector. And the easiest way to get an intuition for a vector is to stop thinking about lists of numbers and start thinking about arrows.
Part 3: A vector is just an arrow
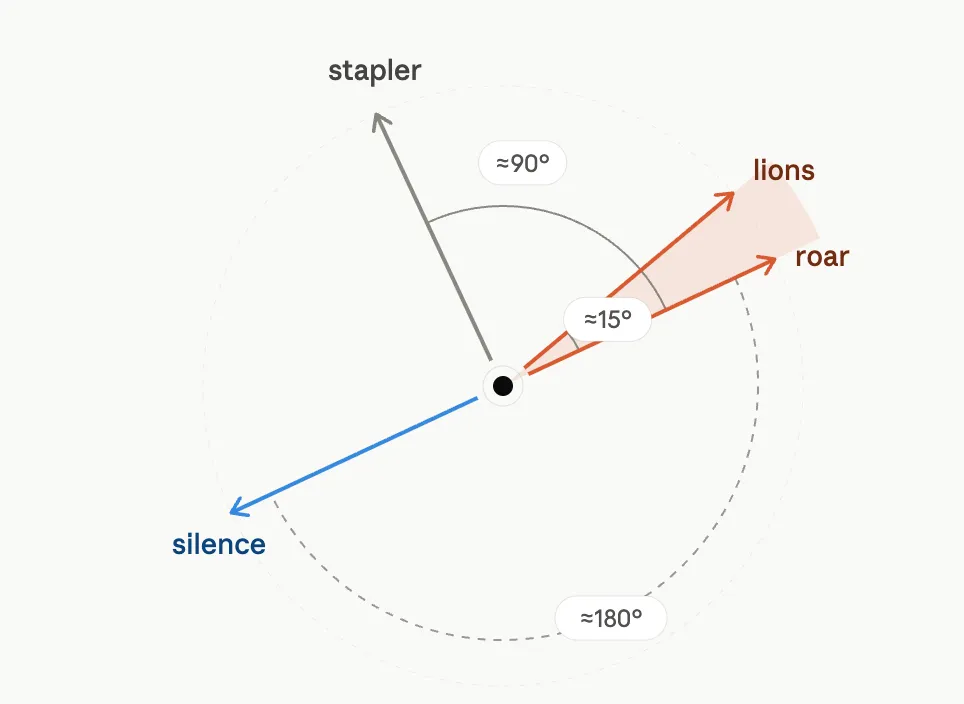
Think of a vector as an arrow pointing somewhere. Picture a map with a dot in the middle, and an arrow drawn from that dot out to a point. Every word gets its own arrow. Words that mean similar things have arrows that point in similar directions, words that don't point in different directions. Comparing two words becomes as simple as comparing where their arrows point.
- Same direction: the words are related.
- Opposite direction (pointing the reverse way): they mean opposite things.
- Right angle (90°): they have nothing to do with each other and are unrelated.
Part 4: Measuring how close two arrows are
"Point the same way" gives us a good intuitive sennse, but LLMs needs an actual number it can work with. That number is the dot product.
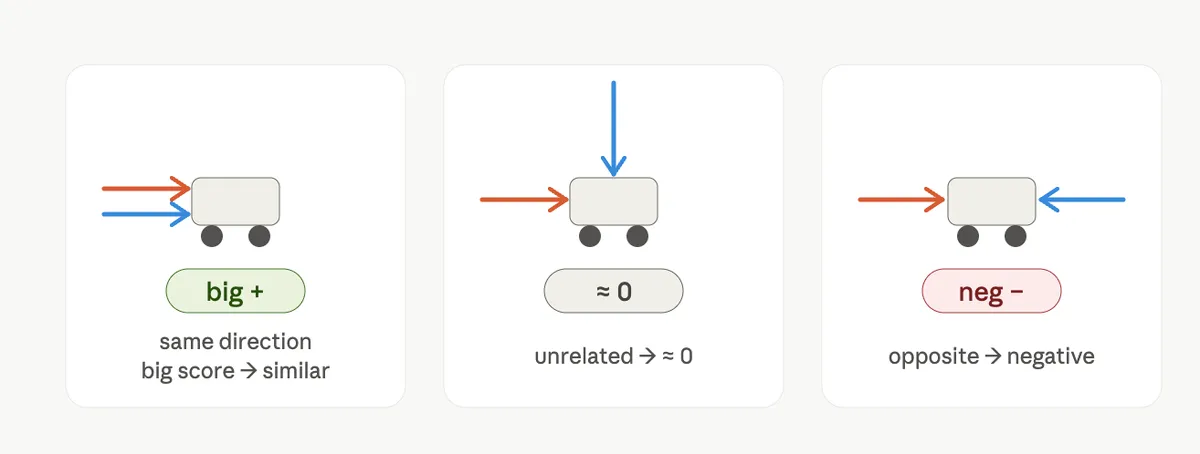
The dot product is simply a score for how close two arrows are. The bigger the score, the more the arrows point the same way, and the more similar the words.
A good way to feel this is to imagine two people pushing the same shopping cart. If they push in the same direction, their forces add up into one strong push, which is a big score. If they push at an angle to each other, only part of the effort actually helps, so the score is smaller. And if they push against each other, the forces cancel out, giving a negative score.
That's really all you need to know: high score means similar, near zero means unrelated, and negative means opposite.
For the math-curious, this is the same cosine from the "cosine law" you may have seen in trigonometry, just reused to compare word arrows.
Part 5: From scores to attention
We now have a closeness score for every pair of words (i.e., the dot product). The problem is that a raw score means nothing on its own. If "roar" and "lions" score an 8, is that a lot? You can't say without seeing how "roar" scores against every other word too. The number only makes sense relative to the rest.
What we really want is a relative measure, i.e., out of all the attention "roar" has to give, what fraction goes to "lions"? A raw dot product can't answer that, so we reshape the scores to answer the question: for each word in the sentence, which other words does it relate to the most, and by how much?
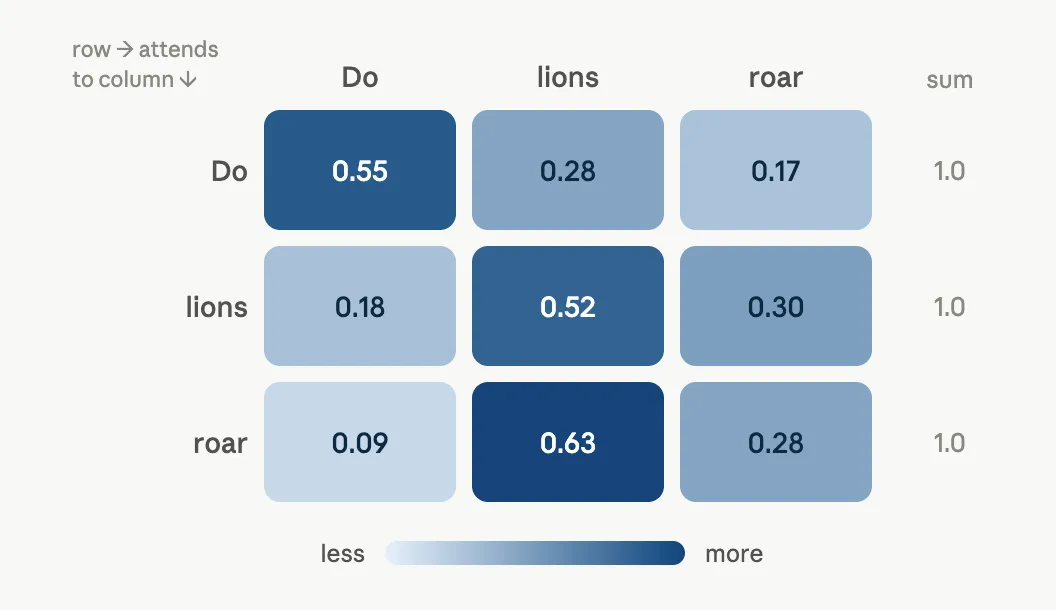
Take "roar". To make sense of it, the model asks who roars? The answer is "lions", not "Do". So "roar" should let "lions" matter a lot and "Do" barely matter at all. Every word does this to every other word: "roar" weighs "lions" and "Do", "lions" weighs "Do" and "roar", and so on across the whole sentence.
To make that usable, we turn each word's raw scores (remember, the dot product) into percentages.
- Give each word a full pizza.
- That word gives other words a slice of their pizza. A word close in meaning gets a fat slice and a distant one gets a sliver.
- Those slices are the weights: how much attention one word pays to another, written as a share of the whole.
Another way to picture it: imagine each word has exactly $1 of attention to spend. It hands more of that dollar to the words it's close to and less to the ones it isn't, but it always spends the full dollar, never more and never less. As a side note, this idea of handing out slices (or attention) to other words is known as softmax, but the name doesn't matter here.
One last question: where do the original arrows come from (the one I made up when I wrote [.056, .089, .034]? That is beyond the scope of this post, but in general, we pick them first at random, and then the model improves them by reading mountains of text, nudging the numbers over and over until close arrows really do line up with similar meanings. That process is known as back propagation and is a whole post on its own.
If you thought I forgot about the question mark, I didn't. The question mark is also a token, no different than a word and treated in the exact same manner. It also has meaning just like the word and an LLM treats it no different than a word. I just wanted to work with only three words in this post.